Comprehensive Data Auditing
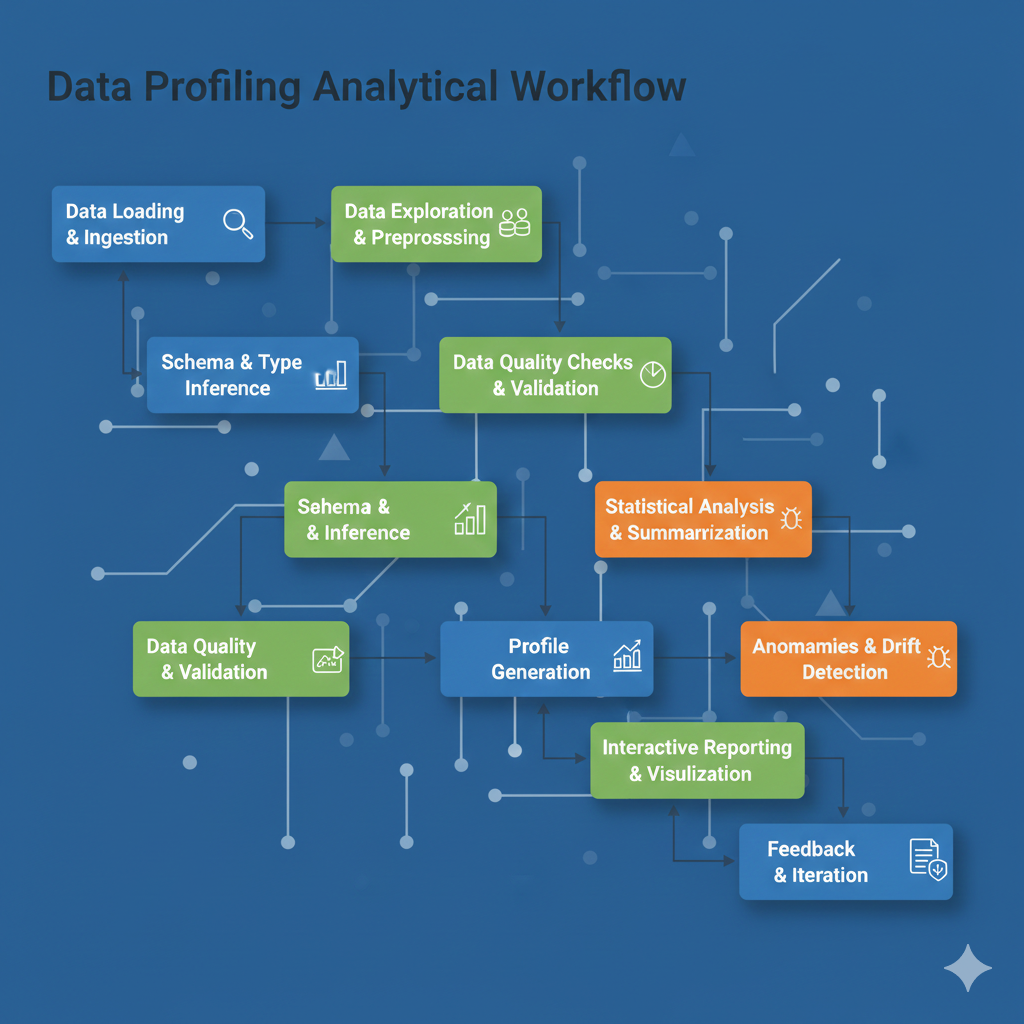
Quality AI starts with quality data. Our Trusted Data Profiler automates the complex task of exploratory data analysis, generating rich visual reports that highlight missing values, skewness, and drift. It uncovering the underlying health of your information before a single model is trained.
By profiling your data early, you can detect anomalies and understand feature interactions, preventing systemic biases from negatively impacting your production performance.
Smart Data Insights
Automated EDA
Generate comprehensive reports with a single command, covering univariate and multivariate analysis for both tabular and time-series datasets.
Correlation Matrices
Visualize highly correlated variables using Spearman and Pearson metrics to prevent redundancy and multicollinearity in feature selection.
Data Quality Alerts
Automatically detect duplicate rows, zero-variance columns, and missing data points that introduce bias or technical errors.
Distribution Analysis
Evaluate histograms, quantile statistics, and extreme values to understand the variance and range of features across the dataset.
Time-Series Profiling
Analyze temporal trends, seasonality, and stationarity to ensure time-dependent models are built on stable foundations.
Comparative Profiling
Compare two versions of a dataset (e.g., Training vs. Validation) to visually inspect for data drift or sampling inconsistencies.
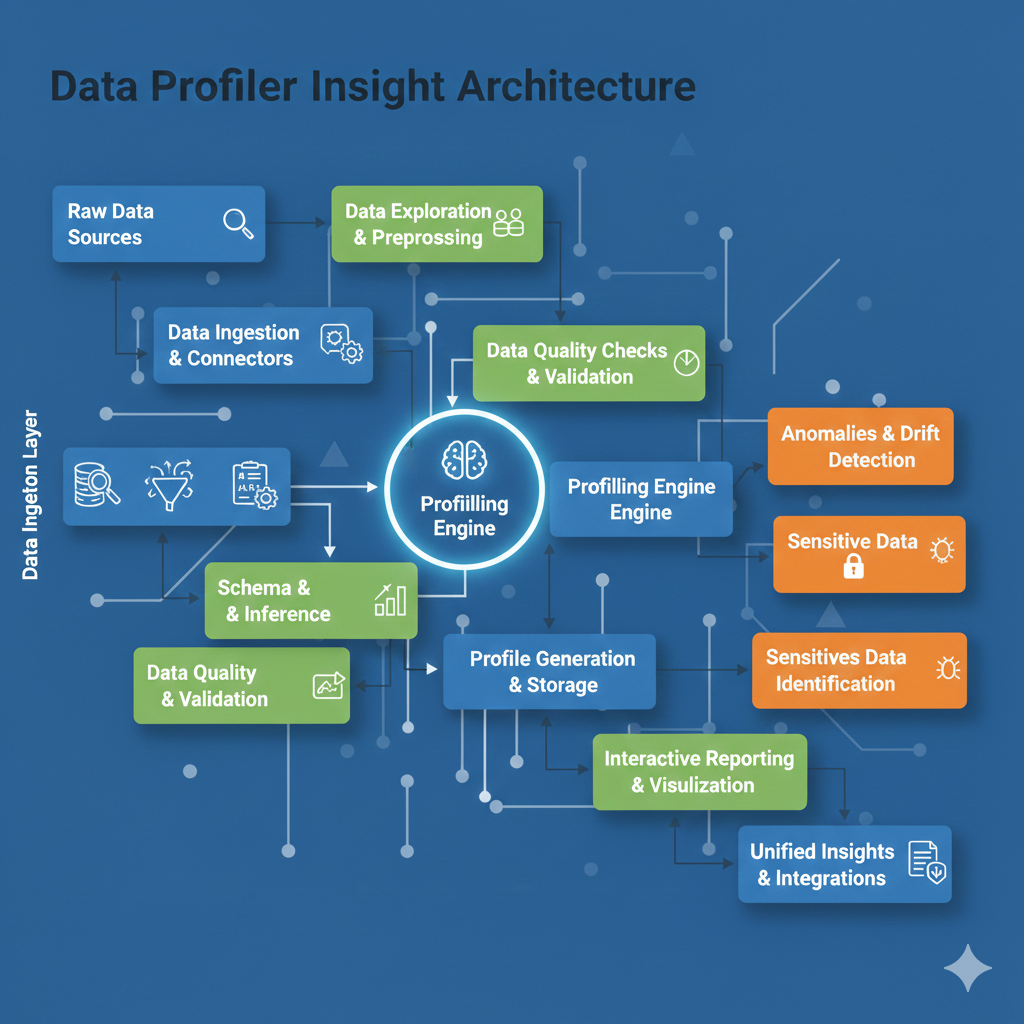
Analytical Insight Architecture
Streamlined Metadata Extraction
Our profiler engine efficiently crawls data structures to extract metadata and type information. It identifies categorical, numerical, and datetime types automatically, applying appropriate statistical tests for each.
Scalable Processing
Designed for big data environments, the architecture utilizes optimized sampling and vectorized calculations to provide near-instant feedback even on high-volume enterprise sources.
High-Quality AI Foundations
Feature Engineering
Identify which variables require transformation or normalization based on skewness and distribution insights provided in the profile report.
Data Cleaning Automation
Use automated quality alerts to prioritize cleaning tasks, focusing on the columns that have the most significant impact on model integrity.
Audit Readiness
Maintain a visual record of dataset health for compliance and governance, proving that models are built on high-fidelity, verified data sources.