Preventing Model Leakage
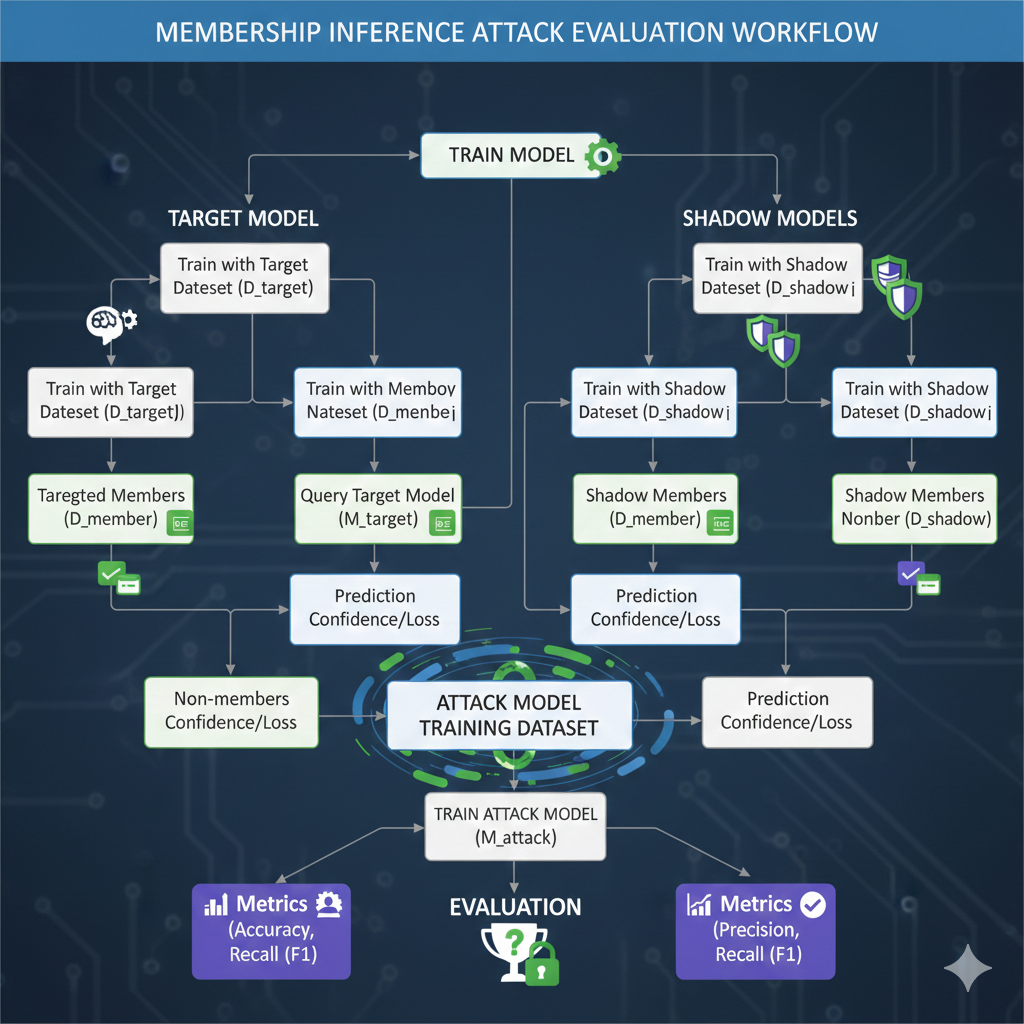
Modern AI models often inadvertently "memorize" their training data. Membership Inference Attacks (MIA) allow us to test if a model's predictions can be exploited to determine if a specific record was part of the training set.
By automating these attacks during the evaluation phase, we identify high-risk samples and determine the model's vulnerability score before it touches production environments, ensuring regulatory and ethical compliance.
Automated Privacy Testing
Membership Inference
Execute automated black-box attacks to measure the probability of training data leakage, ensuring your model doesn't act as an accidental database.
LLM Explainability
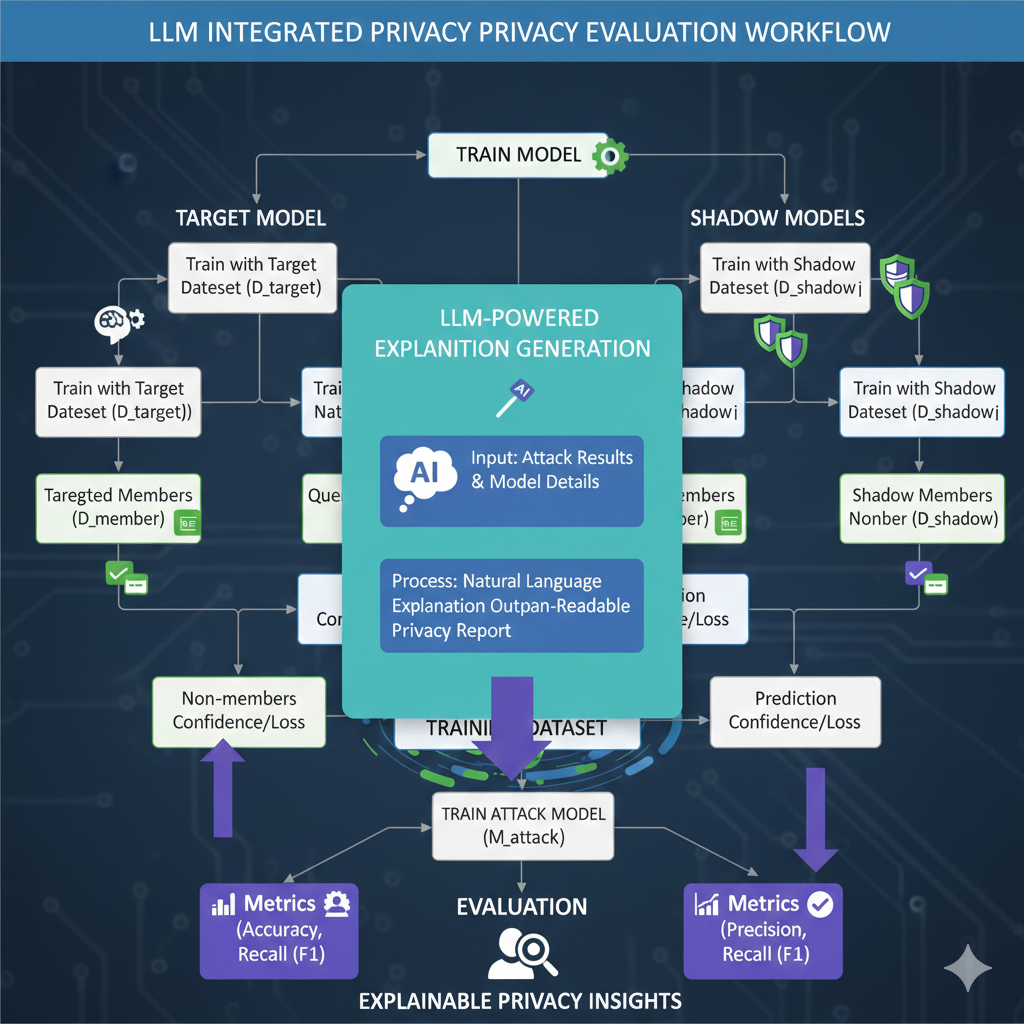
Integrated Large Language Models translate complex technical metrics and attack vectors into readable summaries for stakeholders and compliance teams.
Vulnerability Mapping
Visualize specific data clusters that are most susceptible to inference, allowing for targeted Differential Privacy application or data removal.
Shadow Model Training
Automatically generate shadow models to simulate attacker behavior, providing a realistic assessment of how an external entity could exploit your AI.
Compliance Reporting
Generate automated "Privacy Scorecards" that provide clear pass/fail results for data residency and privacy protection standards.
Remediation Insights
The LLM interface provides specific technical advice on reducing leakage, such as adjusting dropout rates or implementing noise-injection strategies.
Explainable Privacy Architecture
Closing the Explainability Gap
Standard privacy tests produce raw percentages that are often difficult to interpret. Our architecture pipes these results into a specialized LLM agent that explains the contextual risk to non-technical stakeholders.
Continuous Probing
The system performs continuous automated probing of the model's decision boundaries, ensuring that as the model is fine-tuned, its privacy profile remains within safe tolerances.
Secure AI Operations
Medical Data Protection
Ensure that patient-trained diagnostic models cannot be reverse-engineered to reveal individual health status or identity.
Corporate IP Safety
Audit models trained on proprietary codebase or internal documents to ensure sensitive company information isn't retrievable through model outputs.
Consumer Trust
Provide transparent proof to end-users that their personal data has been processed into a model without sacrificing their anonymity.